How we know when decentralization works in government
This essay was originally published on the Centre for Public Impact’s Medium page (13 May 2019).
There is a lively debate raging in the public policy world over the use of evidence, the role of innovation and experimentation, and the importance of “place”. Some public policies clearly benefit from being steered from the national level. Others are much more effective when key decisions are made locally, e.g. in cities.
But how do we know when to centralize and when not to? When is evidence of “what works” useful and when is it not? When is local experimentation crucial for success and when is it a waste of time and resources? When is the “enablement mindset” most needed?
We develop a simple model here that helps us think about these questions in a structured way. Like all models, it is a simplification but it hopefully helps illuminate the questions we should be asking ourselves and others in this debate.
One important caveat: we are looking here at public policies and their effectiveness from a purely empirical perspective. In other words, we are not exploring normative considerations for or against, e.g. decentralization or the use of evidence.
Policymaking is about changing the world in a purposeful way
“Policies” or “strategies” or “interventions” in government are fundamentally about changing the world from the current state into a more desired state, to move it from where it is today to where we want it to be.
There are of course many more reasons why governments sometimes embark on certain policies. Often it is about needing to be seen doing something. But let’s assume for now that our motives are pure and the objective of a policy is to change the world from A to B in some purposeful way.
Assuming that we have a vision or desired state in mind the question becomes: given that we’re here, how do we get there?
The problem of the infinite policy design space
Any intervention or policy will always have multiple dimensions about which we need to make decisions. This is what some people call the “design space” of a policy. This design space is very large, even for simple policies.
Take conditional cash transfers as an example. Conditional cash transfer programmes seek to reduce poverty by making welfare payments conditional on some criteria, e.g. whether the recipient’s children are enrolled in school.
What is the design space for a conditional cash transfer programme?
We need to decide on the amount of money we transfer to beneficiaries. Should it be 10$ per year? 100$ per year? 1000$ per year?
We also need to decide on the frequency of transfers. Should money be given weekly? Monthly? Quarterly?
Next, we need to decide on the conditions attached to the transfer and on how we’ll determine whether the conditions are met. And it goes on and on.
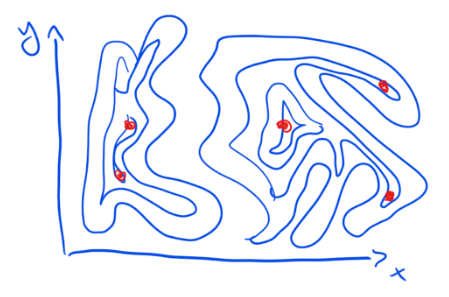
The number of possible combinations is enormous. You could have a programme that transfers $10 weekly and demands that a recipient’s child be vaccinated. Or you could have a programme that transfers $50 on a monthly basis and requires that the children be sent to school. Or you could go for any other conceivable combination of these factors.
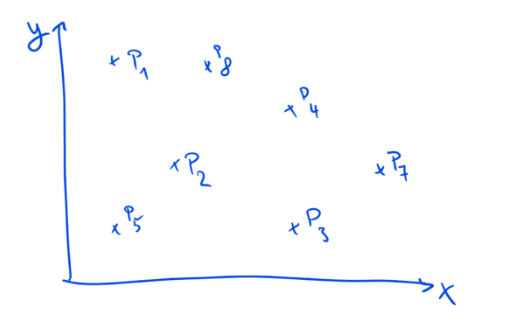
The graph above shows a policy with just two elements. Each dot represents one possible combination. With ten choices to make on each dimension, we would get 100 possible versions of that policy.
Given that most policies involve not just two but hundreds if not thousands of dimensions the “design space” of any policy is — for all intents and purposes — infinite.
What policymakers are interested in is which configuration will yield the best result. In other words, which policy design will be the most effective?
We could, in theory, try out every single conceivable combination in the design space. That would mean trying out a huge number of variants of any policy. Given the number of dimensions of most policies and the combinatorial explosion involved we would quickly be faced with a near-infinite number of policies to try out. That seems impractical, particularly once you factor in that most policies take time to show their results.
Systematically trying out every single combination of parameters is clearly not an option.
What should we do instead then? The answer depends on two things: the shape of the response surfaceand on how much that response surface differs between different places.
Smooth and rugged policies — for some policies small changes don’t make a difference, for others it changes everything
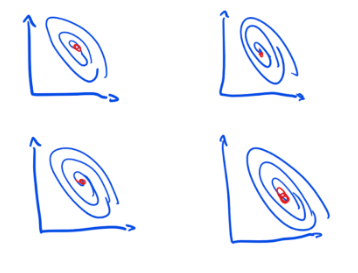
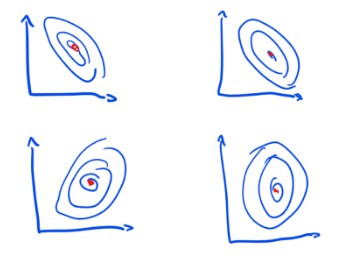
There exist policies for which the response surface is relatively smooth. Small changes in the design space won’t make a big difference.
The sketch below shows such a policy. The red dot shows the optimal configuration. You can imagine this as a hill on a map with the red dot being the highest point.
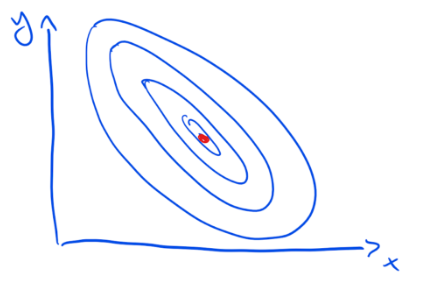
Because the surface is smooth we can systematically search our way to the best solution. For policies with smooth response surfaces, we are much more likely to have either found the optimal place in the design space (the red dot in the sketch) or be somewhere near it.
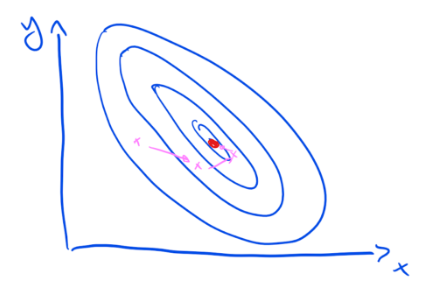
Furthermore, because the surface is smooth there is one right answer to the question of “which configuration of parameters will maximize the effectiveness of this policy?”. Once you found it you should stay there and not change anything. If you deviate from it, you’re doing it wrong.
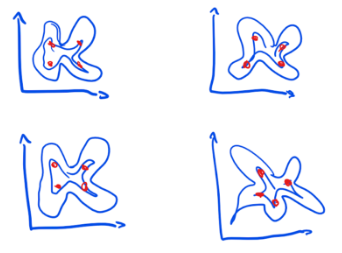
But what if the response surface for a policy isn’t smooth but rugged?
First, we now have multiple “right” answers, i.e. multiple configurations which will produce good results.
Second, finding our way to a good configuration (a red dot in the sketch) is harder because the landscape is more confusing. For those policies, we are much less likely to have either found a global maximum or be near it. This is typical for policies which are complex (rather than just complicated).

To summarize, a policy can either have a smooth or rugged surface. This is, of course, a spectrum with perfectly flat surfaces on one side and crazily spiky surfaces on the other.
There is, however, a dimension beyond rugged-vs-smooth that we need to consider.
The importance of place — some policies work the same way everywhere, others don’t
So far we implicitly assumed that we are implementing this policy only in one place. But almost any policy will, of course, be implemented in more than one place, city, town, region, etc.
If we implement a policy in more than one place each place will have its own response surface. If we look at those local response surfaces and compare them to each other we’ll see one of two situations: it’s possible that they all look the same. Or it’s possible that they look very different.
If they all look the same we have low variability between surfaces. If they all look radically different we have high variability between surfaces.
If we have a smooth surface and low variability it means that no matter where this policy is implemented, the effect will be the same. Changes in the specification of the policy will also have the same effect everywhere.
If the surface is rugged and the variability is low we will get the same effect no matter where we implement the policy. Again, we can “scale” policies to our heart’s content.
If the surface is smooth and the variability is high we will see some differences between places. This means that a policy’s effectiveness will be different in different places — it’ll work everywhere but somewhat better in some places than others.
The most challenging case is, however, when the response surface is rugged and the variability is high.
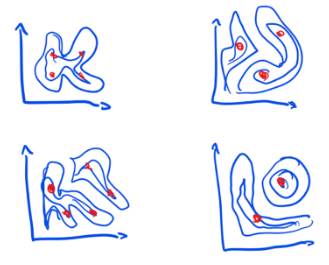
If we implement the policy with the same specification in different places we’ll get radically different results. To achieve similar results we will need different specifications.
What this means for evidence, experimentation, innovation, management, and local decision-making
What does this all mean in practice? This model gives us a useful framework to think about the role of evidence, experimentation, innovation, management, and local vs. central decisionmaking.
Let’s look at the four stylized types of policies in turn.
If we’re looking at a policy that has a smooth response surface and low variability between places life is easy. Evidence about “what works” will travel well. “Scaling” works well because what worked in one place will work in another. That’s why we can pilot a policy in one place then scale it to many more. Top-down control and deciding things at the highest possible (e.g. national) level will also serve us well. In this scenario, there is nothing to be gained from allowing local variation or experimentation.
Consider now a policy with a rugged response surface but still low variability between places. Evidence about “what works” will also travel well. Because the response surface rugged we are, however, less likely to have found the best way of configuring the policy. This means that we would benefit from local experimentation since that increases the chances of hitting on new and better ways of doing things. But if we were to decree this policy and roll it out in an identical fashion across a country we could expect to see the same results no matter where we implement it.
What about a policy that has a smooth response surface but high variability between places? High variability means that unless we have worked out the absolute best way of configuring this policy then the same policy implemented the same way will generate different results in different places. Again this implies that we would benefit from local experimentation.
Finally, let’s look at policies that have a rugged response surface and show high variability between places. Those are policies for which small changes will make a huge difference and for which the effects will vary drastically across places. Evidence about “what works” is not going to tell us much if anything at all in this scenario. Local decision-making and experimentation are essential because anything else will guarantee inferior results.
“Local” or “place” in this context can mean a city, a region or an individual. For some of the most complex social services which governments provide the unit that we should be looking at is the individual. Saying that individuals with complex needs require individualized solutions to their problems is simply saying that the response surface is rugged and the variability between individuals high.
The bottom line is this: unless we’re looking at a policy with a smooth response surface and low variability across places local decision-making and experimentation will always beat control from higher up.
Some things certainly fall into the smooth surface/low variability category but most policy problems arguably don’t. This provides the justification for subsidiarity, the idea that everything should be dealt with at the lowest level possible.
In other words, we should start from the assumption that a problem can be dealt with at the lowest level and only hand it up if there is compelling evidence that it’s necessary. Unless we are very sure we’re in a situation with a smooth response surface and low variability localism will generate better results.
Sources and inspiration
This post draws on many different ideas. Two were particularly influential:
The idea of a response surface is inspired by Lant Pritchett’s talk titled “The debate over RCTs is over: We won, they lost.” (Slides)
The discussion of the role of evidence is influenced by Nancy Cartwright’s and Jeremy Hardie’s book “Evidence-Based Policy: A Practical Guide to Doing It Better”.